Load Testing of 3.6 Release
- Odysseas Pentakalos
Load Testing of 3.6 Release
The load testing was conducted using a standard installation of OpenEMPI 3.6.0 using the recommended JVM (OpenJDK 8), Apache Tomcat 9.0.21 as the application server (Apache Tomcat download site), and PostgreSQL 10 (PostgreSQL site). All software components including the installation of OpenEMPI, the Tomcat application server, the PostgreSQL database and the load testing were all running on the same server running Ubuntu 19.04. The following is the hardware configuration of the server on which the load test was conducted.
| Hardware Configuration |
|---|
CPU: Intel(R) Core(TM) i7-8700 6-Core Processor |
| Disk: 512GB M.2 PCIe x4 SSD + 2TB 7200 rpm Hard Drive |
| Memory: 64 GB, 64GB DDR4 Memory at 2666MHz (4X16GB) |
The purpose of the load test was to determine the performance characteristics of this release of OpenEMPI using the standard installation configuration with no specialized performance tuning performed before the load test was conducted, and using a hardware configuration that is rather minimal for hosting an enterprise application. The load test was repeated using an increasing number of simulated users until either the saturation point of the system was reached or until the number of concurrent users surpassed the number of concurrent users expected in most production environments.
The workload for the load test was defined to be representative of the types of requests that are performed against the system while OpenEMPI is installed in production environments. Each of the simulated users in the load test perform the following sequence of requests:
- A user logs into the system using their credentials
- The user adds a new record (simulating a patient registration)
- The user queries the system for the record that was added using the internal record identifier.
- The user queries the system for the record using an identifier associated with the record (like an MRN or Social Security Number)
- The user queries the system using attributes associated with the record (such as the first and last name)
- The user updates the record (causing the matching algorithm to be invoked again)
- The user deletes the record from the system
Before running the test the test instance of OpenEMPI the database was pre-loaded with one million records. The dataset that was loaded consists of synthetically generated records with 20% of the records being duplicates of other records. The synthetic data generator generates duplicate records by introducing various errors in other records simulating typos, alternate spellings of names, errors typically introduced through OCR of an image, and flipping two different attributes (first name and last name reversed). During each request of a simulated user, the user selects a record from the same dataset that was preloaded on the server, and randomly selects a record that it uses in generating the "Add Record" operation. The simulated user submits the requests to the server using the Entity RESTful Web Services API. By using a fairly high rate of duplicates in the dataset and selecting records from the same dataset for the requests we cause the system to frequently have to update the links associated with the records in the system.
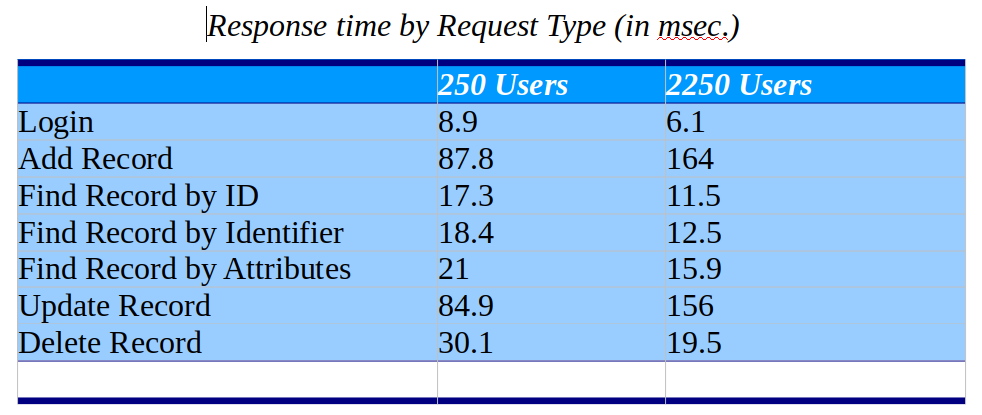
As expected, the system's throughput increased as the number of concurrent users increased. The figure below illustrates the throughput measured after each test as we increased the number of simulated concurrent users generating requests against the instance. The system started to reach saturation at around 2300 users and around that load intensity the average response time starts to increase considerably due to the queueing of request. With 2500 concurrent users the system was processing 252 requests per second.
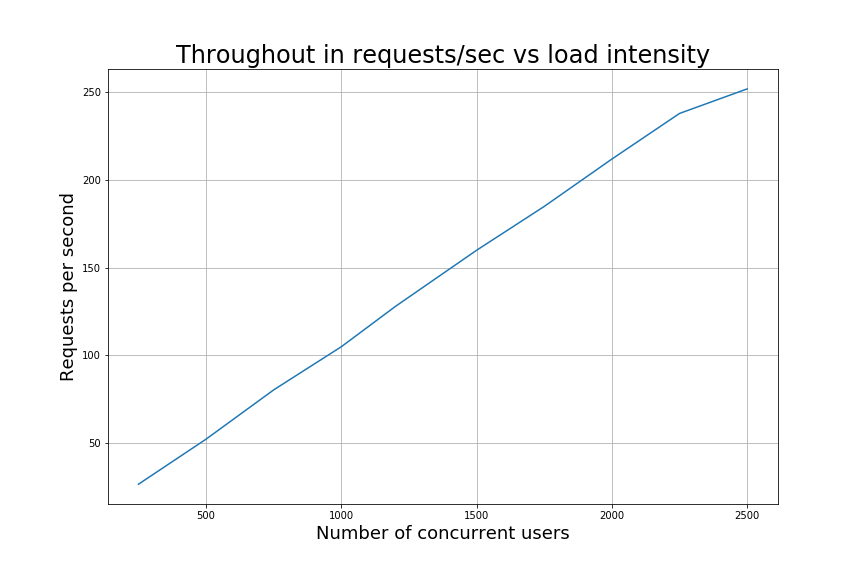
The following table displays the average response time for each request type under two load conditions. The first column displays the response time with 250 concurrent users and the second column with 2250 concurrent users. Even when the system gets close to reaching saturation at 2300 concurrent users every request is still processed in less than 160 msec. As expected, the two request types with the highest response times are the "Add Record" request and the "Update Request". This is due to the fact that both of these requests invoke the matching (and indirectly the blocking) algorithm to identify other records in the system that should or should not be linked with the record that was added or was updated.